 HP G11
HP G11 قیمت سرور HP Gen 10 | مشخصات و خرید سرور اچ پی g10
قیمت سرور HP Gen 10 | مشخصات و خرید سرور اچ پی g10 خرید سرور hp g9 | قیمت سرور اچ پی G9
خرید سرور hp g9 | قیمت سرور اچ پی G9 HP G8
HP G8
مقایسه SAS و SATA
بحث SAS در مقابل SATA اغلب به صورت “قیمت مناسب” نسبت به “کاربرد سازمانی مناسب” مطرح می شود و در این مقاله قصد داریم تا به صورت عمقی به این قضیه نگاهی داشته باشیم.
هارد سرور اچ پی سس چیست را با همدیگر بررسی خواهیم کرد . در مورد سرور hp هم مقالاتی رو می توانید در لینک گزاشته شده مطالعه کنید.
بحث و استدلا های چند ساله ایی در مورد به کارگیری SAS یا SATA در استوریج های سازمانی وجود دارد.
برخی از افراد استفاهد از درایوهای SAS را برای این کار مفید می دانند و برخی دیگر به کارگیری درایوهای SATA را پیشنهاد می دهند. در این مقاله دو جنبه از استدلال های مربوط به SAS و SATA پوشش داده شده اند که جنبه اول مربوط به توضیحات خود داریوها است و جنبه دوم به بررسی جامعیت داده در کانال های SATA و SAS اختصاص داده شده است.

میزان نرخ خطای شدید و سخت (HER)
HER نشان دهنده تعداد بیت هایی است که قبل از رسیدن به احتمال 100 % خطای خواندن داده( یعنی عدم توانایی در خواندن سکتور)، خوانده شده اند. هنگامی که درایویی با خطای خواندن روبرو می شود به این معنی است که کلیه داده های موجود بر روی همان سکتور قابلیت خواندن شدن را ندارند.اکثر سخت افزارها بعد از وقوع این خطا، چند بار دیگر برای خواندن داده هایم وجود بر روی سکتور تلاش می کنند اما در صورتی که نتواند بعد از چند بار تلاش یا سپری شدن مدت زمان خاصی این کار به انجام دهند، گزارش عدم توانایی در خواندن سکتور و به وجود آمدن شکست صادر می شود.
در جدول زیر که مربوط به یکی از مقالات پیشین است، میزان نرخ خطاهای شدید برای درایوهای مختلف و مقدار داده ایی(به پتا بایت) که قبل از وقوع خطای سکتور خراب، خوانده شده اند، لیست شده است.

سطر اول جدول مربوط به درایوهای SATA Consumer است، که معمولا فقط یک رابط SATA دارند ( رابط SAS ندارند). توجه داشته باشید که نرخ خطای سخت اشاره به خطاهای خواندن غیر قابل بازیابی به ازای حداکثر بیت های خوانده شده دارد و همان طور که در اینجا نشان داده شده است برابر 10E14 است.
رابط SATA
سطر دوم جدول مربوط به کلاسی از داریوها است که یا دارای رابط SATA هستند یا دارای رابط SAS( درایو برای هر دو رابط یکسان است). مثلا هاردهای Seagate دو درایو اینترپرایس دارند ب هصورتی که درایو یک رابط SAS 12 Gbps دارد و درایو دومی رابط SATA 6 Gbps دارد. هر دو درایو مشابه هستند اما رابط های متفاوتی دارند. نمونه اولی رابط 12Gbps و دومی رابط 6Gbps SATA دارد اما هر دو دارای نرخ خطای سخت مشابه به میزان 10E15هستند.
کلاس سوم از درایوها، که در ردیف سوم جدول به عنوان “Enterprise SAS / FC” ذکر شده است، معمولا دارای یک رابط SAS است. به عنوان مثال، Seagate دارای یک درایو 10.5K با رابط SAS دارد. میزان خطای سخت برای این درایوها 10E16 است.
آنچه که جدول ما به ما می گوید این است که احتمال مواجه شدن با خطا در هنگام عملیات خواندن برای درایوهای Consumer SATA، 100 برابر درایوهای Enterprise SAS است. در این صورت اگر 10TB داده را از یک داریو Consumer SATA بخوانبد ، احتمال برخورد با خطای خواندن به 100٪ نزدیک می شود.
درایوهای SATA/SAS Nearline Enterprise نرخ خطای سخت را ده بار بهبود داده اند اما همچنان نسبت به درایو Enterprise SAS، احتمال مواجه شدن آنها با خطای سخت، ده برابر بیشتر است. ای مقدار، تقریبا برابر با خواندن 11 ترابایت داده است.
از سوی دیگر، استفاده از درایوهای Enterprise SAS امکان خواندن داده بیشتری را قبل از مواجه شدن با خطای سخت فراهم می کند. در این گونه قبل از آنکه احتمال مواجه شدن با خطای سخت به صد در صد برسی می توان در حدود 1.1 پتا بایت داده را خواند.
زمانی که با یک خطای سخت مواجه می شوید، کنترلر درایو را شکست خورده در نظر می گیرد. با فرض این که درایو، بخشی از یک گروه RAID باشد، کنترل کننده ، بازسازی RAID را با استفاده از درایو اضافی آغاز می کند. گروه های کلاسیک RAID نیزباید تمام دیسک هایی را که در گروه RAID باقی می مانند برای بازگرداندن درایو شکست خورده بخوانند. این به این معنی است که آنها باید 100٪ از درایوهای باقی مانده را بخوانند حتی اگر اطلاعاتی بر روی بخش های درایو وجود نداشته باشد.
به عنوان مثال، اگر یک گروه RAID-6 با 10 درایو کامل داشته باشیم و یک درایو را از دست بدهیم، باید 100٪ هفت باقی مانده به منظور بازسازی درایو شکست خورده و بازیابی raid-6 خوانده شود. در صورتی که هیچ اطلاعاتی وجود نداشته باشد و از گروه RAID-6 نیز استفاده شده باشد، این پروسه باید به صورت کامل انجام شود.
برای نمونه، در یک گروه RAID-6 از ده درایو 4TB Consumer SATA استفاده شده است که مجموعه حجم ذخیره سازی آنها برابر 40 ترا بایت است. با در نظر گرفتن اطلاعات موجود در جدول فوق، هنگامی که حدود ده ترا بایت داده خوانده شود، احتمال مواجه شدن با خطای سخت به نزدیک 100% رسیده است. بنابراین درایو که با این خطا روبرو می شود منجر به عملیات بازسازی می شود.
در نمونه ده دیسک موجود در RAID-6، این امر بدان معناست که در حال حاضر نه درایو باقی مانده است اما قبل از دست دادن محافظت از داده فقط می توانیم یکی از آنها را دست دهیم.
در سناریوی مطرح شده فرض بر این بوده است که یک درایو یدکی داغ (HOT SPARE) وجود دارد که می تواند برای بازسازی ساختار RAID-6 گروهی استفاهد شود. در یک RAID-6 کلاسیک، کل نه درایو باقی مانده باید برای بازسازی خوانده شوند(یعنی 36 ترا بایت).
در این حالت مشکلی وجود دارد به صورتی که احتمال دارد بعد از خواندن ده ترا بایت دیگر درایو دیگری با همین خطا روبرو شود( احتمال وقوع بیار زیاد است چرا که باید 36 ترا بایت داده خوانده شود). در این حالت دو درایو از ده درایو موجود در مجموعه محافظتی با شکست مواجه ی شوند و تعداد کل درایوها به هشت می رسد.
RAID-6 چیست؟
اگر درایو یدکی دیگری وجود داشته باشد، در این صورت برای بازسازی مجموعه RAID-6 باید 32 ترا بایت از هشت درایو باقی مانده خوانده شود. البته در این حالت نیز با توجه به آنکه باید 32 ترا بایت داده خوانده شود احتمال وقوع شکست درایو دیگری وجود دارد. از این رو بازسازی دوم نیز به احتمال قوی با شکست مواجه می شود.
در حال حاضر، در این سناریو سه داریو از ده درایو با شکست مواجه شده اند و امکان بازیابی داده از گروه RAID وجود ندارد.در این نقطه نیاز است تا داده را از نسخه های پشتیبان گیری شده بازیابی کرد. اما خوشبختانه این یکی مبتنی بر درایوهای Consumer SATA نیست چرا که نیاز است تا 40 ترا بایت داده بازیابی شود ودر صورت استفاده از آن به احتمال خیلی قوی چند درایو دیگر را از دست می دهیم. به صورت واضح تر به دلیل امکان وقوع شکست و خرابی درایوها امکان بازیابی 40 ترا بایت با استفاهد از درایوهای Consumer SATA وجود ندارد و دقیقا همان سناریوهای بالایی رخ می دهد.
در نمونه درایوهای SATA/SAS Nearline Enterprise، و با فرض دیسک گروه RAID-6 فوق، احتمال وقوع شکیت دیسک پس از خواندن 100 ترا بایت رخ می دهد. در نمونه درایوهای SAS، احتمال برخورد با خطای سخت بعد از خواندن 1.11 پتا بایت به 100 درصد نزدیک می شود. البته در حال حاضر گروه های RAID با حجم 1.11 پتا بایت رایج نیستند اما در اینده ایی نه چندان دور آنها نیز رایج می شوند.
اطلاعات فوق برای تعیین میزان نرخ خطای سخت تا حدی گیج کننده است بنابراین لازم است تا این اطلاعات را به خوبی و با دقیت مطالعه کنید. در مواقعی هم دیده شده است که این نرخ بر روی دیسک نوشته نشده است در حالت به احتمال قوی میزان نرخ خطای دیسک در حد خوبی قرار ندارد و بسته به میزان خطای سخت و ظرفیت درایو، می توانید اندازه گروه های RAID را به گونه ایی تنظیم کنید که بدون نزدیک شدن به نقطه احتمال 100٪، کار را ادامه دهد.
به کارگیری و استفاده از Consumer SATA برای ایجاد ارایه های ذخیره سازی بدون در نظر گرفتن میزان نرخ خطای سخت درایوهاسبب تنزل کارایی می شود.
نکته دگیری که در اینجا باید به آن توجه شود آن است که با بزرگتر شدن حجم درایوها، سرعت چرخش آنها تقریبا ثابت باقی می ماند از این رو زمنا های لازم برای بازسازی داده به شدت افزایش پیدا می کند و منابع محاسباتی و رایانشی را برای مدت زمان های بیشتری در اختیار خود می گیرد که به نوعی سبب اتلاف منابع، کاهش کارایی و افزایش هزینه ها می شوند.
با ظرفیت فعلی درایوها، زمان برای بازسازی یک درایو می تواند براساس روزاندازه گیری شود و عمدتا مبتنی بر سرعت یک درایو است. در طی زمان بازسازی، در معرض شکست و برخی از انواع آسیب پذیری ها قرار می گیرید و می تواند باعث از دست دادن گروه RAID شود (به عنوان مثال زمان بازسازی کوتاه تر بهتر است). علاوه بر این، در طول دوره بازسازی عملکرد نیز تنزل می یابد، زیرا تمام درایوهای باقی مانده برای بازسازی گروه RAID خوانده می شوند. بنابراین عملکرد به میزان قابل توجهی تنزل می یابد.
در اینجا می توان نکته ایی را مورد توجه قرار داد و آن موضوع عملکرد درایوهای SATA در مقابل SAS بوده است. در واقع هر مسئله ایی که در اینجا در مورد هاردهای سخت گفته می شود برای هاردهای SSD نیز صادق است. این نکته به شدت اهمیت دارد چرا که راه حل های ذخیره سازی وجود دارند که در آنها SATA SSD ها به عنوان حافظه کش برای درایوهای سخت ( یا سطحی از ذخیره سازی ) استفاده می شوند. لازم به ذکر است نرخ خطای سخت SSD ها نیز مشابه با هارد دیسک های چرخشی است و بعد از 10 ترا بایت خواندن داده به مرز وقوع خطای سخت نزدیک می شوند.
جامعیت داده
در ادامه مقایسه درایوهای SAS و SATA، به بررسی جامعیت داده می پردازیم. سوال اصلی اینجاست: سطح اهمیت داد هایتان چقدر است؟ این سوال را از دو جنبه مختلف بررسی و ارزیابی می کنیم:
جنبه شخصی و خانوادگی: آیا شما عکس های دوران خردسالی فرزندانتان را ذخیره کرده اید و قصد دارید آنها را برای مدت طولانی ذخیره کنید و وقتی که به اندازه کافی بزرگ شدند با هم آنها را نگاه کنید؟ چه اتفاقی خواهد افتاد اگر در بلند مدت امکان دسترسی به آنها را از دست دهید یا به صورت کلی از روی درایو پاک شوند؟ به عبارت دیگر میزان تحمل شما در برابر از دست دادن داده های ارزشمند خانوادگی تان چقدر است.
جنبه کاری و تجاری: میزان اهمیت و ارزش داده های تجاری شما چقدار است و ایا می توانید از دست رفتن آنها را تحمل کنید؟ به عنوان مثال برخی از شرکت های بزرگ هوا فضایی در دهه 1940 میلادی که تقریبا هوایپمای زیادی برای پرولز نداشت کلیه اطلاعات و نقشه های مروبط به طراحی های خود را از آن زمان تا کنون نگهداری کرده است. اکنون فرض کنید در زمان حاضر و با استفاهد از نقشه های قدیمی که توسط شرکت ذخیره شده بودند امکان طراحی و پیاده سازی هواپیما وجود داشته باشد. ز
بنابراین باید بتوان دقیقا و عین همان اطلاعاتی که چند دهه پیش ذخیره شده است را بازیابی کرد. هواپیماهای B-52 نمونه ایی از این مثال ها هستند که در سال 1995 میلادی وارد عرضه پرواز شده است و انتظار می رود تا سال 2040 نیز به پرواز خود ادامه دهد که نزدیک به یک قرن را کامل می کند . از این رو باید دسترسی به نقشهه ای طراحی و نحوه پرواز این هوایپما در آن سال ها نیز امکان پذیر باشد.
اطلاعات طراحی در دهه های1940 و 1950 میلادی بیشتر اسناد کاغذی بوده اند اما در حال حاضر این روند به رویکرد دیجیتال تغییر حالت داده است و حصول اطمینان از آنکه بعد از گذشت 100 سال دیگر دقیقا می توان به همین اطلاعات دسترسی پیدا کرد بسیار مهم است. این روند جامعیت داده نام دارد و مهمترین جنبه مدیریت داده در یک شرکت است که باید آدرس دهی شود.
در ادمه این مطلب به فساد اطلاعات خاموش (SDC) بر روی داریوهای SAS و SATA پرداخته می شود که تاثیر زیادی بر روی جامعیت داده دارند. سپس به بررسی نحوه تاثیر T10 DIF/PI و T10-DIX بر بهبود SDC و چگونگی جامع سازی آنها با SAS و SATA پرداخته می شود و در نهایت در مورد سیستم فایل ZFS به عنوان روشی برای کمک به این وضعیت توضیحاتی داده می شود.
فساد خاموش اطلاعات در کانال
یکی از نقاطی که معمولا در مقایسه درایوهای فوق بیشتر مورد توجه قرار می گیرد، خود کانال داده ایی است. کانال ها اشاره به ارتباط از HBA( اداپتور باس میزبان) با خود درایو دارد و از طریق آن داد های می توانند از درایو به کنترلر و برعکس منتقل شوند. همانند بسیاری از چیزهای الکتریکی، کانال ها به دلیل تأثیرات مختلف میزان خطا را دارند.
یکی از جنبه جالب کانال های SAS و SATA این است که این خطاها به آنچه که فساد خاموش داده (SDC) نامیده می شود، منجر می شوند. در اینجا علت استفاهد از واژه خاموش، عدم اطلاع دقیق در مورد زمان رخ دادن فساد اطلاعات و عدم وجود هیچ راه حل خاصی برای شناسایی آن است.
به طور کلی، مشخصات استاندارد برای اکثر کانال ها، خطای 1 بیت در 10E12 بیت است. یعنی، به ازای هر 10E12 بیت که از طریق کانال منتقل می شود، یک بیت داده به صورت خاموش خراب می شود. این عدد به عنوان نرخ SDC تعداد بیت هایی در نظر گرفته می شود که قبل از وقوع با خطای خاموش انتقال یافته اند. هر چقدار میزان SDC بیشتر باشد، نیاز است تا قبل از وقوع خطا، داده های بیشتری از طریق کانال عبور داده شوند.
جدول زیر تعدادی از SDC های مربوط به نرخ SDC های معین و نرخ انتقال اطلاعات در طول یک سال را نشان می دهد.
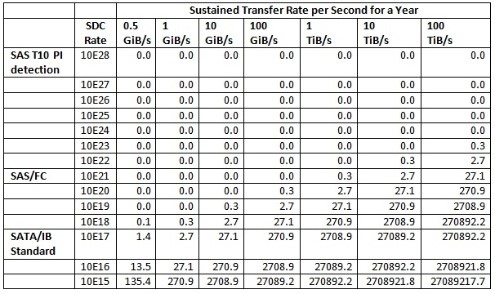
جدول2. تعداد خطاها به صورت تابعی از نرخ SDC و توان عملیاتی
برای مثال اگر نرخ SDC برابر 10E19 باشد و نرخ انتقال داده برابر 100GiB/s باشد به احمتال قوی شما در یک سال با 27.1 SDC ( هر 2 هفته یک بار) روبرو می شوید. برای سیستم های ذخیره سازی فوق سریع که از کانال های SATA با نرخ انتال داده ایی در حدود 1 ترا بایت بر ثانیه کار می کنند، با 2.087 SDC( هر 3.2 ساعت) روبرو می شوید.
از سوی دیکر کانال های SAS دارای نرخ SDC در حدود 10E21 هستند. بنابراین اجرا با سرعت 10 GiB/s، به احمتال قوی هیچ میزان SDC را در سال نمی دهد. اگر اجرا در حدود 1 TiB/s باشد، میزان SDC در سال برابر 0.3 خواهد بود.
اهمیت این جدول نباید فراموش شود. کانال SATA در مقایسه با یک کانال SAS با SDC بیشتر روبرو است. کلمه کلیدی در کلمه اختصاری SDC همان سکوت یا خاموش است. این بدان معنی است که شما نمیتوانید بگویید وقتی که یا داده خراب است.
بحث T10
گاهی اوقات حتی SDC با 10E21 نیز کافی نیست. سیستم هایی با نرخ انتقال 1 TiB/s فعالیت می کنند. همچنین سیستم های جدید با سرعت انتقال 10 TiB/s يا بالاتر نیز امکان خریداری و استفاده شدن را دارند. حتی با کانال های SAS، در 10 TiB/s شما احتمالا با 2.7 SDC در یک سال روبرو خواهید شد. البته این عدد در نگاه اول کوچک به نظر می رسد اما به دلیل بالا بودن اهمیت جامهیت داده، این عدد بسیار بزرگ است.
اگر فساد اطلاعات به صورت دنباله ژنوم شخصی رخ دهد چه؟ در این صورت به طور ناگهانی کل فضای ذخیره سازی دچار اپیدمی شده و داهد های آن از بین می روند. علاوه بر این، اگر کانال خراب شود و میزان خطای بیت کانال پایه به تعداد بدی پیش می رود، چه اتفاقی خواهد افتاد؟ به عنوان مثال، اگر نرخ کانال از 10E12 به چیزی کوچکتر، شاید 10E11.5 یا 10E11 کاهش یابد، چه اتفاقی خواهد افتاد؟ در حاالت حداقلی، سیستم هایی با نرخ داده بسیار بالا می توانند چندین SDC بیشتر از انتظارات را ببینند.
کمیته ای وجود دارد که بخشی از کمیته بین المللی استاندارد های فناوری اطلاعات (INCITS) است و به نوبه خود به موسسه استاندارد ملی آمریکا (ANSI) گزارش می دهد. این کمیته، به نام کمیته فنی T10 در رابط های ذخیره سازی SCSI ، مسئول استانداردهای معماری SCSI است و تنظیم اکثر مجموعه فرمان های استاندارد SCSI (که تقریبا در تمام رابط های I / O مدرن استفاده می شود) است. سازمان T10 یک استاندارد جدید به نام T10 PI / DIF ایجاد کرده است(PI= حفاظت از دیسک اطلاعات، DIF= دیسک حوزه جامعیت داده). این استاندارد تلاش می کند که از طریق سخت افزار و نرم افزار به یکپارچگی داده ها پاسخ دهد. استاندارد T10-DIF سه فیلد (CRC’s) را به بخش دیسک استاندارد اضافه می کند. یک نمودار برای یک بخش دیسک 512 بایت با فیلدهای اضافی در زیر نشان داده شده است:

تصویر1. نقشه داده T10-DIF
در یک سکتور 512 بایتی (که در شکل قبل به صورت 0 تا 511 بایت نشان داده شده است)، سه فیلد اضافی وجود دارد، و به این ترتیب یک تکه 520 بایتی (نه توانی از دو) وجود دارد. اولین فیلد اضافی یک گارد داده 2 بایتی است که یک CRC از سکتور 512 بایتی است. این رشته به اختصار GRD نامیده می شود. فیلد دوم یک تگ برنامه کاربردی 2 بایتی است، و به اختصار APP نامیده می شود. فیلد سوم یک فیلد مرجع 4 بایتی است، که به اختصار REF نامیده می شود. با استفاده از T10-DIF، HBA یک CRC محافظ 2 بایتی (GRD) را قبل از آنکه تمام سکتور 520 بایتی به درایو منتقل شود را به بخش داده 512 بایتی اضافه می شود . سپس درایو می تواند برای بررسی خطا GRD CRC را نسبت به CRC سکتور 512 بایتی بررسی کند. این امر به صورت قابل توجهی احتمال فساد خاموش اطلاعات از HBA به درایو دیسک را کاهش می دهد.هارد سرور اچ پی سس
T10-DIF به این معنی است که درایوها قادر به اداره و کنترل کردن سکتورهای 520 بایتی (و نه تنها 512 بایتی) هستند. علاوه بر این، اگر درایوها سکتورهای 4096 بایتی داشته باشند، استاندارد T10-DIF به سکتورهای 4،104 بایتی تغییر می کند. سازندگان HBA و دیسک امروزه از T10-DIF پشتیبانی می کنند. به عنوان مثال، LSI دارای HBA است که با T10-DIF سازگار است.
یک روش بصری برای تفکر در مورد حفاظت این روش در شکل زیر ارائه شده است:
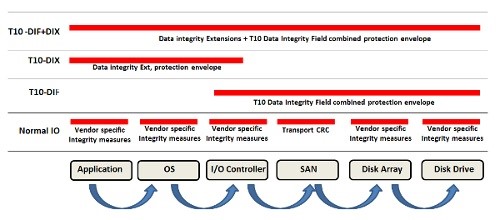
تصویر 2. حفاظت T10 در مسیر داده ایی
در پایین این تصویر، مسیر انتقال داده از نرم افزار به دیسک درایو نشان داده شده است و این احتمال وجود دارد که یک شبکه ذخیره سازی(SAN) در مسیر به وجود آید( این روند با عنوان شبکه SAS نیز شناخته می شود). ردیف اول در بالای اجزای داده، با برچسب “Normal IO”، نشان دهنده بررسی های مربوط به یکپارچگی داده ها است که فروشندگان انجام داده اند. به دلیل عدم هماهنگی با همدیگر احتمال و ورود فساد خاموش اطلاعات دربین مراحل مسیر داده وجود دارد.
سطر بعدی که با عنوان T10-DIF نامگذاری شده است نشان می دهد که در کجا این استاندارد وارد تصویر می شود. HBA چک سام را محاسبه می کند و آن را در یک میدان GRD سکتور 520 بایتی قرار می دهد. سپس این داده کل مسیر را تا درایو طی می کند. در این حالت می توان از طریق بررسی چک سام GRD و چک سام محاسبه شده داده، از صحت آن اطمینان حاصل کرد. T10-DIF نیز برخی از تکنیک ها و راه حل های محافظت از تمام داده های درایورا در اختیار قرار می دهد.
اگر شما به جدول SDC برگردید، می بینید که هنگام استفاده از T10-DIF با یک کانال SAS، SDC به 10E28 افزایش می یابد. برای یک سیستم ذخیره سازی که در طول سال به 100 TiB / s می رسد، احتمالا یک SDC تنها در کانال SAS مواجه نخواهد شد. همچنین نکته ای که باید به آن توجه شود میزان گذردهی درایو در طول یک سال است از این رو یک سیستم ذخیره سازی در حال اجرا با 100 TiB / s ، در طول یک سال تقریبا دارای توان عملیاتی 3,153,600,00 TiB (حدود 31،536،000 اگزابایت) است.
استفاده از T10-DIF 7 مرتبه بزرگی را به حفاظت SDC یک کانال SAS اضافه می کند (10E21 تا 10E28). از این رو در حال حاضر، SAS + T10-DIF ، 11 مرتبه بهتر از کانال SATA است (10E28 در مقابل 10E17).
یک استاندارد دوم دیگر به نام T10-DIX وجود دارد که چک سام را از برنامه محاسبه می کند و آن را در سکتور 520 بایتی درج می کند ( بخش APP). در نمودار قبلی حفاظت T10-DIX با استفاده از برچسب “T10-DIX” نشان داده شده است. این شیوه محافظتی کی تواند برای بررسی یکپارچگی داده ها مورد استفاده قرار گیرد.
اگر به نمودار پیشین نگاه کنید، برنامه یا چیزی نزدیک به آن، یک CRC 2 بیتی (تگ) ایجاد می کند و آن را در 524 بایت داده قرار می دهد. این کاراجازه می دهد تا بتوان داده ها را تا حد زیادی در HBA بررسی کرد. در این صورت HBA می تواند یک چک سام را انجام دهد و آن را به T10-DIF اضافه کرده وبه درایو ارسال کند.
اگر شما به قسمت بالای دیاگرام قبلی نگاه کنید(“T10-DIF + DIX”)، می توان دید که چگونه افزونه های T10 از یکپارچگی داده ها در طول انتقال ازبرنامه به درایو اطمینان حاصل می کنند . این همان چیزی است که در صورت نیاز به جامعیت داده واقعا به آن نیاز است.
چند نکته در مورد T10-DIF(PI) و T10-DIX وجود دارد. اول آنکه نمی توان بدون اعامل تغییرات در POSIX حوزه برنامه کاربردی را از طریق لایه VFS عبور داد. دوم آنکه در نمونه NFS، توانایی انتقال بخش 520-bute به احتمال زیاد اتفاق نخواهد افتاد، مگر اینکه پروتکل اساسی ( و POSIX) تغییر داده شوند. این بدان معناست
که اگر بخواهید یکپارچگی داده ها را از برنامه به HBA (T10-DIX) میزبان بخواهید، در حال حاضر NFS نمی تواند پروتکل خوبی برای این کار باشد. با در نظر گرفتن توضیحاتی که تا به حال ارائه شده اند مشاهده می شود که T10 به صورت کامل در مورد SAS بحث شده است چرا که امکان پیاده سازی این استاندارد با SATA وجود ندارد.
توجه داشته باشید که بحث جامعیت داده درباره کانال ها است و نه درایوها. بنابراین هر دستگاه ذخیره سازی که از کانال SATA استفاده می کند از میزان نرخ SDC که قبلا بحث شد، رنج می برد. در صورتی که دستگاه ذخیره سازی از کانال SAS استفاده کند آنگاه دارای SDC مشابه است و توانایی استفاده از T10-DIF/PI و T10-DIX را دارد به صورتی که می تواند سطح SDC را نسبت به SATA بهبود ببخشد. به وضوح روشن است که چنین قابلیتی در هاردهای SSD وجود دارد. SATA SSD هایی که از کانHل SATA استفاده می کنند نست به SSD هایی که از کانال های SAS استفاده می کنند دارای SDC بسیار ضعیف تری هستند.
سیستم های ذخیره سازی زیادی وجود دارند که از تایر کش ( سطوح دسته بندی داده ها) SSD ها استفاده می کنند. مفهوم اصلی استفاده از SSD خیلی سریع در ابتدی یک درایو با ذخیره سازی بالا است. روش کلاسیک مورد استفاده، به کار گیری درایوهای SAS برای ایجاد بانک پشتیبان در کش سیستم و استفاده از SSD ها به عنوان لایه کش خواندن و نوشتن است. اکثر این گونه راه حل ها از کانال های SAS بر روی بانک پشتیبان استفاده می کنند که حاصل آن به دست آوردن نرخ قابل قبول SDC است. به هر این گونه روشها از SATAT SSD ها در لایه کشینگ استفاده می کنند.
برخی از این لایه ها توانایی اجرا در 10 GiB/s را دارند. با یک کانال SATA به احمتال قوی می توانید به مقدار 27.1 SDC در سال دست یابید در حالی که این مقدار برای دستگاههای مبتنی بر کانال در SAS در سال می تواند بدون SDC باشد. حاصل این روند نشان می دهد که استفاهد از راه حل ذخیره سازی با به کارگیری کانال SATA ضعیف ترین کارایی را به همراه دارد. با استفاده از این مفهوم، می توانید یک لایه ذخیره سازی مبتنی بر کانال SAS با نرخ بسیار خوب SDC را در کنار یک لایه ذخیره سازی مبتنی بر کانال SATA با نرخ SDC بسیار ضعیف در نظر بگیرید.
هارد سرور اچ پی سس استفاده از ZFS می تواند مشکل SATA را حل کند؟
یک سوال که ممکن است در این مورد داشته باشید این است که آیا سیستم فایلی مانند ZFS ، علی رغم محدویتهای موجود در کانالSATA ، اجازه استفاهد از درایوهایی که از طریق کانال های SATA وصل شده اند را می دهد؟ ZFS بر روی یکپارچگی داده تمرکز می کند و اطلاعات را کنترل می کند بنابراین نباید برخی از مشکلات کانال SATA را اصلاح کند؟ در ادامه به تشریح و جزییات مربوط به سوالات فوق پرداخته می شود.
ZFS چک سام ها را می خواند وهنگامی که داده ها را در دستگاه ذخیره سازی می نویسد، چک سام های هر بلوک را محاسبه می کند و آنها را همراه با داده ها در دستگاه های ذخیره می نویسد. چک سام ها به صورت اشاره گر به بلوک نوشته می شوند و به عنوان قسمتی از اشاره گر بلوک محاسبه و در آن ذخیره می شود. هنگامی که بلوک داده ایی خوانده شود، چک سام محاسبه می شود و با نمونه ذخیره شده در اشاره گر بلوک مقایسه می شود. اگر با هم مطابق باشند داده از سیستم فایل به تابع فراخوانی عبور داده می شود. اگر چک سام منطبق نباشد، داده با استفاده از یکی از روش های ایینه ایی یا RAID تصحیح می شود.
توجه داشته باشید که چک سام ها بر روی بلوک ها ساخته می شوند و اجازه می دهند تا بلوک های بد در صورتی که منطبق نباشند و اطلاعات لازم برای بازسازی آنها وجود داشته باشند، مجددا ساخته شوند. اگر بلوک ها تکرار شده باشند، آنگاه نمونه تکرار شده آن استفاهد می شود و برای جامعیت تست می شود. اگر بلوک ها با شیوه RAID ذخیره شده باشند، داده ها همانند شیوه RAID و از طریق بلوک های باقی مانده بازسازی می شوند. به هر حال نکته کلیدی که در حالت های شکیت چنداگنه چک سام باید به آن توجه داشت، فساد در نظر گرفته شده است و باید از طریق پشتیبان بازیابی شود.
ZFS می تواند در برخی موارد از یکپارچگی داده استفاده کند. ZFS اطلاعات چک سام ها را در حافظه قبل از انتقال اطلاعات به درایوها محاسبه می کند. بسیار بعید است که اطلاعات چک سام در حافظه فاسد شود. پس از محاسبه چک سام، ZFS اطلاعات را از طریق کانال در درایو ها می نویسد و چک سام های مربوط به اشاره گرهای بلوک را نیز در آنجا می نویسد.
از آنجا که داده ها از طریق کانال آمده است، پس ممکن است که داده ها توسط یک SDC خراب شود. در این صورت ZFS اطلاعات خراب شده را (یا داده یا چک سام و احتمالا هر دو) را می نویسد. هنگامی که داده ها خوانده می شوند، ZFS قادر به بازیابی اطلاعات صحیح است، زیرا یا یک چک سام خراب برای داده ها (ذخیره شده در نشانگر بلوک) را شناسایی می کند یا خود داده های خراب را شناسایی می کند. در هر صورت، داده ها را از یکی از روش های آینه ایی یا RAID باز می گرداند.
نکته کلیدی این است که تنها راه کشف بد بودن داده ها خواندن مجدد آنهاست. ZFS دارای ویژگی به نام “scrubbing” است که درخت داده ها را پیمایش می کند و چک سام ها را در اشاره گرهای بلوک و خود داده ها بررسی می کند. در صورت تشخیص مشکل ، داده ها اصلاح می شوند. اما اسکراب گرفتن CPU و منابع حافظه رامصرف خواهد می کند و سبب تنزل عملکرد ذخیره سازی می شود. لازم به ذکر است که اسکراب در پس زمینه سیستم عامل انجام می شود.
اگر قبل از انجام اسکراب توسط ZFS که بر روی داده هاب خراب اثر می گذارد، خطای سختی ( به علت SDC در کانال SATA) را دریافت کنید، آنگاه به احمتال زیاد نخواهید توانست داده را بازیابی کنید. هنگامی که داده ها خراب شوند از چک سام ها می توان برای اصلاح آنها استفاده کرد، اما در این حالت بلوک و اشاره گر به بلوک ها نیز از بین رفته اند و بازیابی آنها را تا حد بسیاری زیادی مشکل کرده است.
با توجه به میزان نرخ خطای درایو در درایوهای Consumer SATAدر بخش اول و اندازه گروه های RAID و همچنین میزان SDC موجود در کانال های SATA ، ترکیب این رویدادها می تواند یک امکان متمایز باشد (مگر اینکه شما شروع به اسکراب کردن داده ها با سرعت بسیار بالا کنیدبه گونه ایی که داده های جدید بلافاصله اسکراب شوند، این امر کارایی سیستم فایل را تنزل می دهد). بنابراین ZFS می تواند در کاهش SDC به کانال SATA کمک کند، زیرا می تواند داده های خراب شده توسط کانال SATA را بازیابی کند، اما برای انجام این کار، تمام داده هایی که نوشته شده نیز باید خوانده شوند (برای اصلاح داده ها). این بدین معنی است که برای نوشتن بخشی از داده ها، باید چک سام را در حافظه محاسبه کنید، سپس چک سام محاسبه شده را به همرها داده در سیستم ذخیره سازی بنویسید، داده و چک سام را مجددا بخوانید، چک سام ذخیره شده با نمونه محاسبه شده را مقایسه کنید، و احتمالا داده خراب را بازیابی کنید، چک سام جدید را محاسبه کرده و آن را در دیسک بنویسد. این روند نشان میدهد که برای نوشتن بخشی از داده به چه حجم عظیم کاری نیاز است.
موضوع دیگر که می تواند که در اینجا مطرح شود، مقایسه عملکرد SAS و SATA است. در حال حاضر SATA دارای یک رابط 6 گیگابیتی است و به جای دو برابر کردن رابط برای رفتن به 12 گیگابیت در ثانیه، تصمیم به تغییر چیزی به نام SATA Express شد. SATA Express یک رابط کاربری جدید است که از دستگاههای ذخیره سازی مبتنی بر SATA و PCI EXPRESS پشتیبانی می کند. این ویژگی جدید باید در سال 2014 معرفی و استفاده می شد و اوج کارایی آن برای دستگاههای SATA قدیمی تا 6Gbps بود و مقدار آن برای دستگاههای pci بین 8 تا 16 گیگا بیت بر ثانیه بود. البته در حال حاضر رابط های SAS 12Gbps نیز وجود دارند و انتظار می رود در سال های آتی این مقدار به 24 نیز برسد.
خلاصه و مشاهدات هارد سرور اچ پی سس
داریوهای SATA در مقایسه با درایوهای SAS نرخ خطای سخت بسیار کمتری دارند. درایوهای Consumer SATA نسبت به درایوهای Enterprise SAS ، 100 برابر بیشتر با خطای سخت مواجه می شوند. درایوهای SATA/SAS Nearline Enterprise دارای نرخ خطای سختی هستند که فقط 10 برابر بدتر از درایوهای Enterprise SAS است. به همین دلیل هنگام استفاهد از درایوهای SATA، اندازه گروه های RAID محدو می شود و امکان از دست دادن چند دیسک بسیار بالا می رود به صورتی که حتی RAID6 هم نمی تواند کمکی برای بازیابی داده ها بکند. این نتایج نشان می دهد که استفاده از درایوهای SATA در گروه های بزرگ RAID، به علت ثابت ماندن آرایه در میانه عملیات بازسازی سبب تنزل شدید کارایی می شود.
درصد بروز وقوع فساد خاوش دیسک (SDC) در SATA بیشتر از SAS است به صورتی که احتمال وقوع SDC در SATA چهار بابر بیشتر از احتمال وقع SDC در SAS است. برای نرخ های داده ایی موجود در سیستم های بزرگتر امروزی، با به کارگیری کانال SATA و سرعت 0.5 GiB/s احتمال مواجه شدن با SDC در سال وجود دارد ( 1.4 بار در هر سال) اما به کارگیری کانال های SAS این احتمال را به صورت کلی از بین می برد. البته لازم است کانال SAS را در 1 TiB/s به صورت سالانه اجرا کنید. در این حالت میزان وقوع SDC در سال به میزان 0.3 است. با به کار گیری استاندارد T10-DIF نرخ SDC برای کانال SAS به نقطه ایی می رسد حتی با به کارگیری نرخ داده ایی 100 TiB/s، میزان آن در سال به صفر می رسد . این روند حتی با به کارگیری T10-DIX می تواند بهتر نیز شود چرا که مسائل مربوط به جامعیت داده از برنامه تا HBA و تا درایو آدرس دهی می شوند. البته این حالت نیاز به اعمال تغییرات ذر POSIX دارد.
از آنجایی که در SATA قابلیت به کارگیری دو استاندارد فوق وجود ندارد.به منظور تامین جامعیت داده در سیستم های مبتنی بر SATA باید نرخ مناسبی از SDC انتخاب شود. از این رو SATA و کانال های مبتنی بر SATA برای سیستم های خانگی مناسب هستند که از دو درایو SATA استفاده می کنند . به کارگیری ترکیبات ذخیره سازی مبتنبر SATA در سازمان هایی که حجم زیادی از اطلاعات با ارزش را دارند توصیه نمی شود و به عنوان ترکیب بدی محسوب می شود.
سیستم هایی فایلی نظیر ZFS که چک سام را به صورت مناسبی انجام می دهند می توانند از طریق نوشتن چک سام با بلوک های داهد ایی به بحث های جامعیت داده کمک کنند اما گزینه ایی عالی محسوب نمی شوند.ZFS برای بررسی فساد داده ها باید دوباره آنها را بخوانید. این امر واقعا عملکرد را کاهش می دهد و باعث افزایش مصرف CPU می شود (به یاد داشته باشید که ZFS از RAID استفاده می کند). تاثیر نهایی بر نرخ SDC با به کار گیری ZFS مشخص نیست، اما می تواند به کاهش آن کمک کند.
به طور فزاینده ایی، راه حل هایی وجود دارند که از تایر کشینگ کوچکتر و پر سرعت در جلوی یک تایر بزرگتر با سرعت کمتر استفاده می کنند. مثال کلاسیک استفاده از SSD در مقابل دیسک های چرخشی است. هدف از این پیکر بندی استفاده از درایوهای پرسرعت مثل SSD برای کش کردن داده هایی که است که تعداد دسترسی به آنها زیاد است. از این رو در سطوح پااین تر از دیسک های چرخشی با ظرفیت بالا و سرعت به مراتب کندتر استفاهد می شود تا بتوان داده هایی که میزان دسترسی به آنها کمتر است را در سطوح پایین ذخیره شوند.
از لحاظ مفمهومی ابتدا داده بر روی SSD نوشته می شود و سپس به دیسک منتقل می شود. به هر حال در این نوع پیکربندی جامعیت کلی داده توسط ضعیف ترین لینک که قبلا بحث شد محدود می شود. گزینه دیگر استفاده از SSD های مبتنی بر شکاف های توسعه به جای SSD های SATA است. البته در این مقاله اطلاعاتی در مورد میزان نرخ SDC این گونه SSD ها منتشر نشده است. علاوه بر این، من اعتقاد ندارم که این دو درایو دو پورت وجود دارد به طوری که شما می توانید آنها را بین دو سرور برای انعطاف پذیری داده ها استفاده کنید (در بسیاری موارد، اگر حافظه پنهان کاهش یابد، کارایی کل راه حل ذخیره سازی کاهش می یابد).
اکنون به پایان این مقاله رسیدیم و به شما به جهت خواندن آن تبریک می گویم. مقاله کمی طولانی بود اما در آن لازم بوده تا برخی واقعیت های فنی ارائه شود. کاملا واضح است که برای راه حل های ذخیره سازی با اندازه بزرگ که در آن یکپارچگی داده مهم است، SATA راه حل مناسبی نیست. اما این به این معنی نیست که کل SATA ارزش خاصی ندارد. به هر حال SATA راه حل بسیار مناسبی برای دسک تاپ های خانگی و مکان هایی که حجم داده زیادی ندارند، به شمار می رود . بنابراین وقت خود را برای درک نیازهای یکپارچگی داده ها و نوع راه حل مورد نیاز خود بگذارید.